Fallstudie: Präzises Prompting als Schlüssel zur Lösung von Logikrätseln mit ChatGPT
Die Herausforderung der künstlichen Logik
Der provokante Titel „Ist die KI so schlau wie eine Hauskatze?“ in der „NZZ am Sonntag“ vom 1. Juni 2025 war mehr als nur eine rhetorische Spielerei. Für mich als zertifizierte AI-Prompterin war es eine direkte Einladung zur praktischen Überprüfung.

Bildquelle: NZZ am Sonntag, 1. Juni 2025
Die im Artikel aufgeworfene Frage, ob ein Sprachmodell wie ChatGPT komplexe Logikaufgaben lösen kann, formuliert eine zentrale Herausforderung und ein realistisches Testszenario für die tatsächlichen Fähigkeiten moderner KI-Systeme.
Diese Fallstudie beschreibt das durchgeführte Experiment. Ziel ist es, zu zeigen, wie eine sorgfältige Methodik die logischen Analysefähigkeiten von KI-Modellen effektiv aktiviert und nutzt.
Es wird gezeigt, dass der Erfolg weniger von einer vermeintlichen autonomen „Intelligenz“ der KI abhängt, sondern massgeblich von der Qualität der menschlichen Führung – insbesondere durch die strategische Kombination von visuellen und textuellen Anweisungen.
Das Dokument gliedert sich wie folgt: Zunächst wird die detaillierte Methodik des Experiments vorgestellt, die als Framework für die präzise Steuerung der KI diente. Anschliessend folgt die Analyse der Ergebnisse anhand konkreter Beispiele, aus denen im nächsten Schritt allgemeingültige Prinzipien für erfolgreiches KI-Prompting abgeleitet werden.
Ein abschliessendes Fazit fasst die Kernerkenntnisse zusammen. Die folgende Untersuchung beweist, dass der Schlüssel zu diesem perfekten Ergebnis ausschliesslich in einer rigorosen und reproduzierbaren Methodik liegt, die nun im Detail vorgestellt wird.
Methodik des Experiments: Ein Framework für präzise KI-Führung
Eine systematische und reproduzierbare Methodik ist entscheidend, um die Leistung von KI-Modellen objektiv zu bewerten und verlässliche Ergebnisse zu erzielen. Der fundamentale Unterschied zwischen einer vagen, konversationellen Anfrage („Was meinst du dazu?“) und einer präzisen, führenden Instruktion, wie sie in diesem Experiment zur Anwendung kam, bestimmt über Erfolg oder Misserfolg.
Testumgebung und Versuchsaufbau
Für das Experiment wurde ein klar definierter, multimodaler Prozess etabliert. Als KI-Modelle kamen GPT-4o sowie GPT-4.1 zum Einsatz, die beide identische und korrekte Ergebnisse lieferten. Der dreistufige Versuchsaufbau war wie folgt:
- Rekonstruktion der Aufgaben: Alle acht Logikrätsel aus dem Zeitungsartikel wurden originalgetreu in der Design-Software Canva nachgebaut.
- Visueller Input: Diese Rekonstruktionen wurden als hochauflösende Bilddateien exportiert, um sie der KI als visuellen Kontext zur Verfügung zu stellen.
- Kombinierter Input: Jedes Bild wurde zusammen mit einer spezifischen textuellen Anweisung in die ChatGPT-Schnittstelle hochgeladen, um die visuellen Daten mit einem klaren analytischen Auftrag zu verknüpfen.
Die Kerninstruktion: Analyse des Master-Prompts
Um das Modell präzise zu steuern, habe ich einen Prompt entwickelt, der ChatGPT in einen passenden Analysemodus versetzt.
Du bist ein präziser KI-Analyst für visuelle Logikrätsel, Denkmuster und Aufgaben aus klassischen Intelligenz- und Logiktests. Bitte analysiere das folgende Bild als Teil eines IQ- oder Intelligenztestes. Deine Aufgabe: Betrachte die geometrische Struktur, Farbgebung, Zahlenverteilung oder Grössenverhältnisse. Finde logisch-mathematische oder visuelle Zusammenhänge (z. B. Additionen, Multiplikationen, Differenzen, Spiegelungen, Rotationen, Symmetrien, Paare, Muster).Erkläre deinen Denkprozess logisch Schritt für Schritt,ohne Kommentare oder Mutmassungen, sondern nüchtern und präzise. Gib am Ende nur eine eindeutige Lösung an, falls mehrere Möglichkeiten bestehen, entscheide dich logisch. Wichtig: Nicht raten. Nicht ausrechnen, wenn nicht ausdrücklich notwendig. Keine allgemeine Beschreibung, sondern lösungsorientierte Deduktion. Modus: Logik-Modus, Mustererkennungs-Modus, Visueller IQ-Test-Modus.
Die Wirksamkeit dieses Prompts liegt in seiner strukturierten Zusammensetzung. Jede Komponente hat einen spezifischen strategischen Zweck:
| Komponente | Funktion und strategischer Zweck |
| Rollenzuweisung | Weist der KI die Rolle eines „KI-Analysten“ zu, um den Fokus auf nüchterne Analyse statt auf kreative Interpretation zu legen. |
| Aufgabenbeschreibung | Definiert klar die Aufgabe: Erkennung von logisch-mathematischen oder visuellen Zusammenhängen in geometrischen Strukturen, Farben etc. |
| Prozessvorgabe | Fordert eine schrittweise, logische Erklärung des Denkprozesses, um die Nachvollziehbarkeit der Lösung zu gewährleisten. |
| Verhaltensregeln (Constraints) | Setzt klare Grenzen: "Nicht raten", "Nicht ausrechnen, wenn nicht notwendig", "keine Mutmassungen", um präzise, deduktive Antworten zu erzwingen. |
| Modus-Aktivierung | Schaltet das Modell explizit in den "Logik-Modus", "Mustererkennungs-Modus" und "Visueller IQ-Test-Modus", um die relevanten Algorithmen zu priorisieren. |
Diese präzise methodische Vorbereitung war die unabdingbare Voraussetzung für die fehlerfreien Resultate, die im Folgenden analysiert werden.
Ergebnisse und Analyse ausgewählter Beispiele
Das Gesamtergebnis des Experiments untermauert die Wirksamkeit der gewählten Methode eindrücklich: acht von acht Aufgaben wurden korrekt gelöst, es gab null Fehler.
Dieser Erfolg ist kein Zufall, sondern das direkte Resultat der präzisen Prompting-Strategie, die der KI einen klaren analytischen Rahmen vorgab. Die Analyse zweier repräsentativer Beispiele verdeutlicht die entscheidenden Erfolgsfaktoren.
Beispiel 1: Grössenlogik in Kreisen
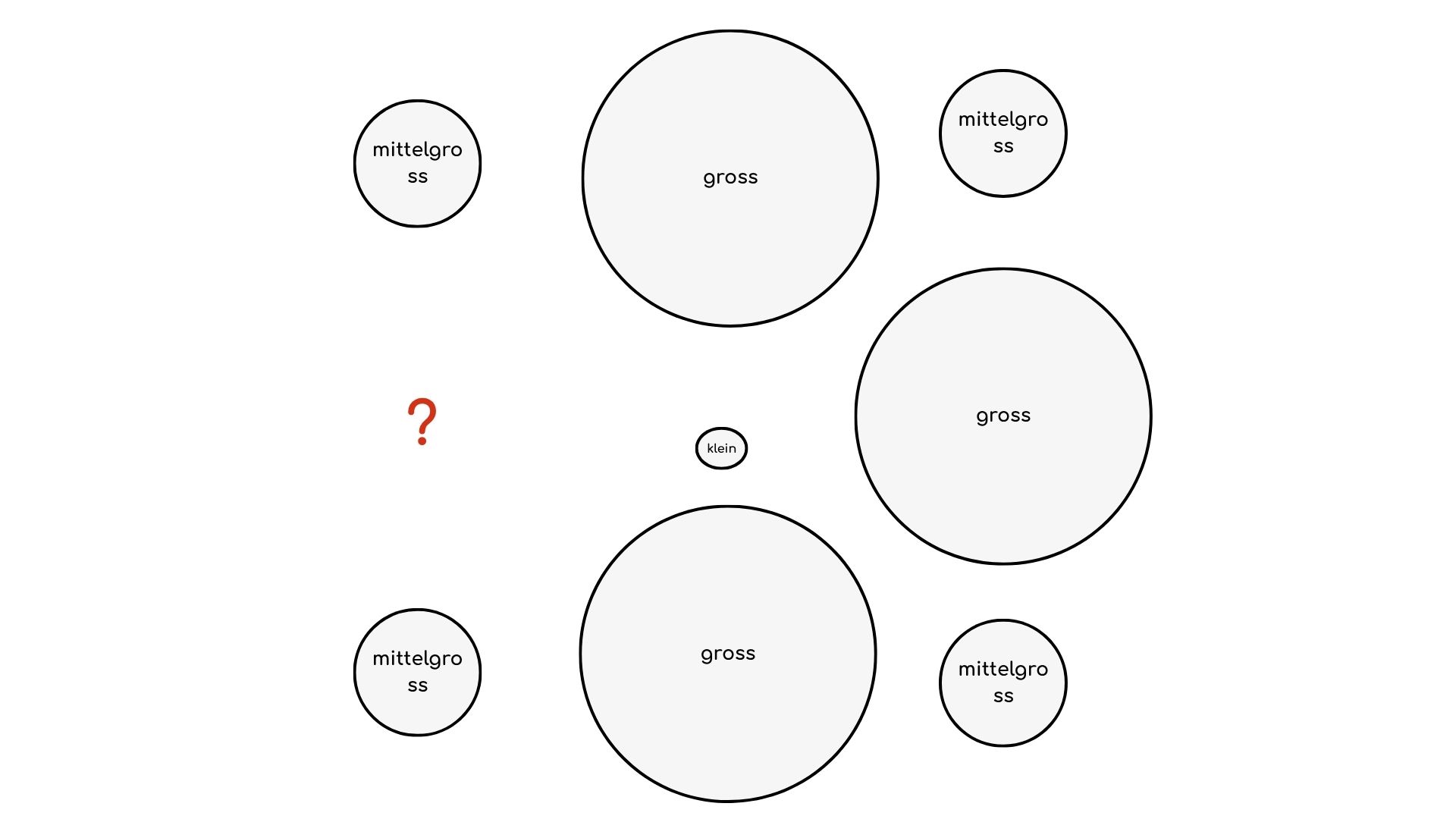
Problemstellung
Bei dieser Aufgabe bestand die Herausforderung darin, aus einem Muster von Kreisen unterschiedlicher Grösse die korrekte Grösse des fehlenden Kreises zu bestimmen.
Analyse des Erfolgsfaktors
Der entscheidende Faktor, den ein Prompting-Spezialist hier gezielt steuern muss, ist die sprachliche Führung. Relative Begriffe wie „gross“, „mittelgross“ und „klein“ sind ohne Kontext bedeutungslos.
Angesichts dieser Mehrdeutigkeit habe ich diese Einordnung bewusst bereitgestellt. Der Erfolg bestand nicht darin, dass die KI die Definition eigenständig erarbeitete, sondern darin, dass menschliche Fachkenntnis die erforderlichen Rahmenbedingungen schuf.
Die Anweisung „Nicht ausrechnen“ verhinderte zudem, dass das Modell in unnötige Berechnungen abdriftete, und lenkte den Fokus wie beabsichtigt auf reine Mustererkennung und Logik.
Beispiel 2: Farblogik im Quadrat
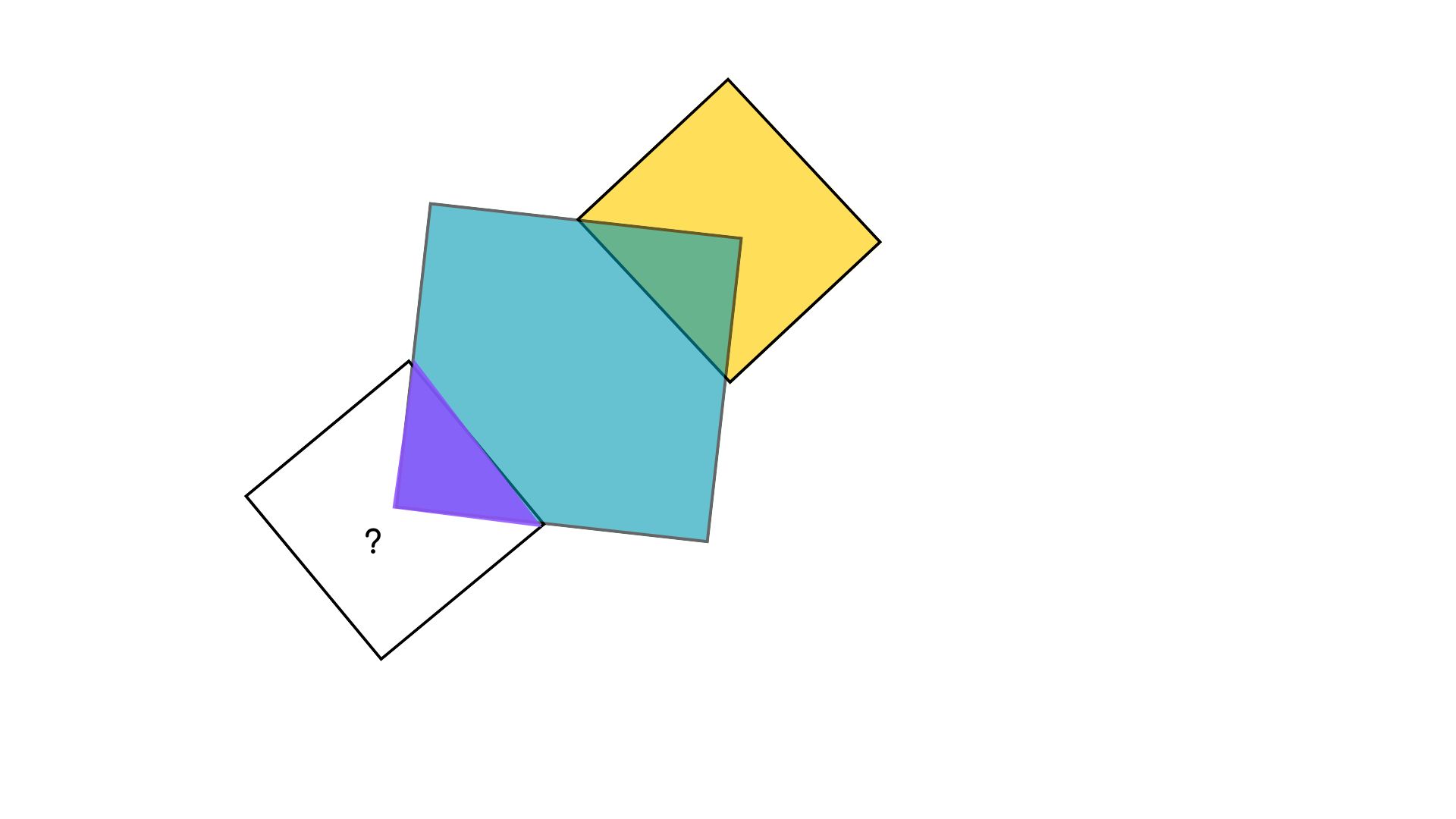
Problemstellung
Hier musste die korrekte Farbe in einem komplexen visuellen Muster identifiziert werden. Die Schwierigkeit lag nicht nur im Muster selbst, sondern auch in der potenziellen semantischen Falle der Fragestellung.
Analyse des Erfolgsfaktors
Der Erfolg hing von einem einzigen Wort in der Anweisung ab. Die Frage wurde bewusst formuliert als: „Welche Farbe folgt im Quadrat mit dem Fragezeichen?“.
Eine alternative Frage wie „Welche Farbe hat das Quadrat?“ hätte die KI zur falschen Antwort „weiss“ verleitet, da das Feld visuell weiss war. Das Wort „folgt“ agierte hier als präziser analytischer Operator, der das Modell von einem deskriptiven Modus („Was sehe ich?“) in einen extrapolierenden Modus („Was ist die logische Konsequenz im Muster?“) umschaltete.
Es demonstriert eindrücklich eine klassische Lektion in semantischer Genauigkeit.
Resultate der weiteren Tests

Die übrigen sechs Logiktests wurden nach exakt demselben Schema durchgeführt: Jedes Rätsel wurde als Bild nachgebaut und zusammen mit dem Master-Prompt hochgeladen.
Ohne Ausnahme löste die KI auch diese Aufgaben korrekt. Dieser durchgängige Erfolg über die gesamte Testreihe hinweg bestätigt, dass die Methode nicht nur bei Einzelfällen, sondern systematisch und reproduzierbar funktioniert.
Die konsistenten Ergebnisse bilden die Basis für die Ableitung allgemeinerer, übertragbarer Prinzipien des professionellen Promptings.
Ableitung von Prinzipien für erfolgreiches KI-Prompting
Die Extraktion von allgemeingültigen Prinzipien aus einer konkreten Fallstudie ist für die Ausbildung von KI-Spezialisten von unschätzbarem Wert.
Sie wandelt die Frage des "Was" der Ergebnisse in das "Warum" und "Wie" der zugrunde liegenden Regeln um und sorgt so dafür, dass der Erfolg wiederholbar ist.
Als logische Konsequenz der hier präsentierten Evidenz lassen sich drei Kernprinzipien für die professionelle Steuerung von Sprachmodellen ableiten.
- Prinzip 1: Instruktion ist Führung, nicht Konversation. Die Fallstudie belegt, dass Sprachmodelle am effektivsten arbeiten, wenn sie nicht wie ein menschlicher Gesprächspartner, sondern wie ein hochspezialisiertes Werkzeug behandelt werden. Der entscheidende Leitsatz lautet: „Prompting ist Führen mit Sprache, nicht ein Gespräch auf Zuruf.“ Vage Anfragen führen zu unvorhersehbaren Resultaten, während klare, unmissverständliche und strukturierte Anweisungen das Fundament für qualitativ hochwertige und zielgerichtete Ergebnisse bilden.
- Prinzip 2: Multimodales Potenzial durch sprachliche Steuerung entfalten. Die strategische Nutzung der multimodalen Fähigkeiten war ein zentraler Erfolgsfaktor. Dabei fand eine klare Arbeitsteilung statt: Das Bild liefert die Rohdaten – das visuelle Rätsel. Der Text-Prompt hingegen liefert den analytischen Rahmen und die exakten Interpretationsregeln. Dies wurde im Farblogik-Rätsel perfekt demonstriert, bei dem das Bild die visuelle „Frage“ stellte und der Text-Prompt den entscheidenden analytischen Operator „folgt“ lieferte. Die Schlussfolgerung ist eindeutig: „Wer GPT-4o multimodal nutzt, muss beide Seiten meistern“.
- Prinzip 3: Prompting ist ein erlernbares sprachliches Handwerk. Erfolgreiches Prompting ist kein Zufallsprodukt, sondern ein Handwerk, das auf Präzision, Erfahrung, Übung und Bildung basiert. Vergleichbar mit dem Erlernen jeder anderen Fachkompetenz erfordert es ein tiefes Verständnis für die Funktionsweise von Sprache und die Fähigkeit, Anweisungen so zu formulieren, dass sie für eine Maschine eindeutig interpretierbar sind. Wer KI sinnvoll und professionell einsetzen will, muss dieses sprachliche Handwerk beherrschen.
Diese Prinzipien bilden die Quintessenz der Fallstudie und dienen als Leitfaden für die effektive Zusammenarbeit mit fortschrittlichen KI-Systemen.
Fazit und Ausblick
Die vorliegende Fallstudie demonstriert schlüssig, dass der fehlerfreie Erfolg bei der Lösung von acht anspruchsvollen Logikrätseln direkt auf eine präzise, methodische und multimodale Prompting-Strategie zurückzuführen ist.
Die Kombination aus klaren visuellen Inputs und einer exakten sprachlichen Führung ermöglichte es den KI-Modellen GPT-4o und GPT-4.1, ihre analytischen Fähigkeiten gezielt und fehlerfrei einzusetzen.
Die zentrale Erkenntnis dieses Experiments lässt sich daher in einem Satz verdichten: Der Schlüssel zur Erschliessung des wahren Potenzials von KI liegt nicht in ihrem autonomen „Denken“, sondern in der Fähigkeit des Menschen, sie durch Sprache präzise zu führen.
Diese Analyse versteht sich als ein praktischer Beitrag, um den gesellschaftlichen Dialog über Künstliche Intelligenz mit Kompetenz und Neugier zu bereichern. Sie zeigt, dass die Fähigkeiten einer KI kein statischer Wert sind, sondern dynamisch durch die Qualität der Interaktion geformt werden.
Denn wer die Sprache präzise beherrscht, aktiviert Potenzial, bei Menschen wie beim Prompting.
Nun sind Sie an der Reihe: Testen Sie, validieren Sie und meistern Sie diese Fähigkeit.